스마트폰앱
- 전화 다이얼러
- 모바일 VOIP
- 안드로이드 프로그램
- 아이폰 앱 프로그램
- 네트워크 프로그램
- JAVA 자바
- UI DESIGN
- android JNI
- http post get
- 휴대폰 해외로밍


 친추
친추 카톡
카톡
라인상담
라인으로 공유
페북공유
◎위챗 : speedseoul

1. C 언어에서 정수 표현에 대한 정리
이 글에서는 메모리에 값을 대입하기 위해 정수 표현을 사용해야 합니다. 그래서 이 글에서 사용하는 정수 표현에 대해 먼저 간단하게 설명하고 메모리 정렬 규칙에 대해서 설명하겠습니다.
C 언어에서는 정수를 3가지 형태로 보통 표현하는데 8진수, 10진, 16진수를 사용합니다. 그런데 이 표현 중에서 16진법 표현을 메모리 관련 글에서 많이 사용합니다. 왜냐하면 16진수 한자리는 16개의 숫자와 문자로 구성('0'~'9', 'A'~'F') 되기 때문에 4비트 크기의 정보라서 16진수 숫자를 아래와 같이 두 자리로 적으면 그 표현이 1바이트를 의미하기 때문입니다.
그래서 이 글에서는 소스에서 적은 상숫값을 즉시 바이트 단위의 메모리로 나누어서 생각이 가능한 16진법 표현을 사용해서 설명하도록 하겠습니다. 그리고 C 언어에서는 정수 상수를 적으면 int형 자료형으로 적용되기 때문에 0x12라고 적으나 0x1234라고 적으나 모두 int 자료형으로 처리되어 4바이트를 의미합니다. 즉, 0x12라고 적으면 컴파일러는 이 값을 0x00000012의 생략형으로 처리합니다.
하지만 이 글에서는 설명을 위해서 0x12는 1바이트 의미하고 0x1234는 2바이트를 의미하는 것처럼 설명하겠습니다.
2. 메모리의 바이트 정렬이란?
컴퓨터 시스템의 메모리는 비트 단위로 연산이 가능하지만 메모리 관리는 바이트 단위로 합니다. 그래서 운영체제는 메모리를 1바이트 단위로 번호를 매겨 관리하고 그 번호를 '메모리 주소'라고 합니다.
따라서 메모리를 한 바이트씩 처리할 때는 메모리의 관리 단위와 일치하기 때문에 사용자가 지정한 값을 그대로 메모리에 넣으면 됩니다. 예를 들어, 아래와 같이 data 변수와 temp 변수에 값을 대입하면 data 변수도 1바이트이고 0x12 값도 1바이트이기 때문에 다른 규칙 없이 값이 1 바이트 메모리에 그대로 저장됩니다.
0x12와 0x34 값은 아래의 그림처럼 각각 1바이트의 메모리에 저장됩니다.

하지만 2 바이트 이상으로 표현된 상숫값을 2 바이트 크기의 메모리에 저장할 때는 데이터를 어떻게 저장할 것인지 규칙을 정해야 합니다. 예를 들어, 아래와 같이 2 바이트 크기의 0x1234 값을 2 바이트 크기의 메모리에 저장한다면 1 바이트씩 나누어서 0x12, 0x34 순서로 저장할 수도 있고 0x34, 0x12 순서로 저장할 수도 있기 때문입니다.
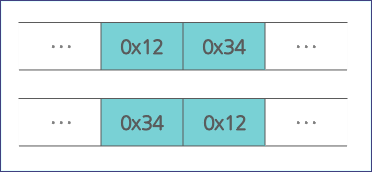
이렇게 2바이트 이상의 메모리를 사용할 때 어떤 순서로 배열할 것인지가 '바이트 정렬'입니다. 사실 이 바이트 정렬 규칙이 하나로 통합되었으면 정말 좋았을 텐데 시스템의 고유 특성이라서 하나로 통합되지 못하고 CPU 계열에 따라 다르게 적용되어 있어서 개발자는 자신이 사용하는 시스템이 어떤 바이트 정렬을 사용하는지 잘 이해하고 있어야 합니다.
3. 바이트 정렬의 종류
바이트 정렬 규칙은 보통 '빅 엔디언(Big Endian)'과 '리틀 엔디언(Little Endian)'으로 나누어지는데 하나씩 설명하면 다음과 같습니다.
[ 빅 엔디언 - Big Endian ]
예전 Unix 시스템을 동작시키던 대형 컴퓨터에서는 RISC(Reduced Instruction Set Computer) 계열의 CPU를 많이 사용했습니다. 이 RISC 계열의 CPU는 바이트 정렬을 큰 자릿수부터 적는 방식을 사용하고 이 방식을 '빅 엔디언'이라고 부릅니다. 예를 들어, 아래처럼 data 변수에 0x12345678이라는 4바이트 크기의 값을 대입하면 값이 4 바이트에 걸쳐서 메모리에 저장해야 하기 때문에 0x12 값부터 저장하는 방식이 '빅 엔디언'입니다.
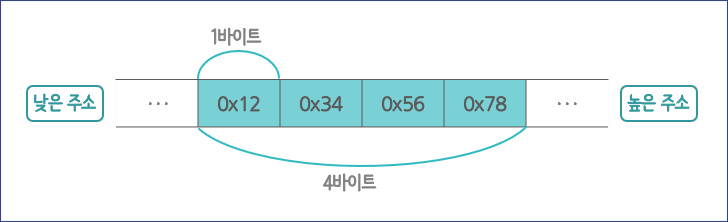
정숫값이 0x12345678이라고 하면 0x12 값이 0x34 값보다 수치상으로는 작지만 0x12345678라는 숫자에서 보면 0x12000000과 0x340000이기 때문에 0x12가 더 높은 자릿수입니다. 그래서 위 그림처럼 0x12부터 메모리에 나열하게 됩니다.
[ 리틀 엔디언 - Little Endian ]
우리가 많이 사용하는 Intel이나 AMD는 CISC(Complex Instruction Set Computer) 계열의 CPU를 제공합니다. 이 CISC 계열의 CPU는 바이트 정렬을 작은 자릿수부터 적는 방식을 사용하고 이 방식을 '리틀 엔디언'이라고 부릅니다. 예를 들어, 아래처럼 data 변수에 0x12345678이라는 4바이트 크기의 값을 대입하면 값이 4 바이트에 걸쳐서 메모리에 저장해야 하기 때문에 0x78 값부터 저장하는 방식이 '리틀 엔디언'입니다.
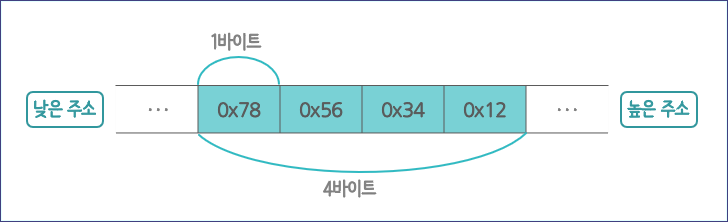
정숫값이 0x12345678이라고 하면 0x12 값이 0x34 값보다 수치상으로는 작지만 0x12345678라는 숫자에서 보면 0x12000000과 0x340000이기 때문에 0x12가 더 높은 자릿수입니다. 그래서 위 그림처럼 0x12가 메모리의 가장 마지막 위치에 나열됩니다.
그래서 우리가 일반적으로 사용하는 컴퓨터가 대부분 인텔 CPU를 사용하고 Windows 운영체제에서 프로그램하기 때문에 '리틀 엔디언' 방식으로 정숫값이 나열된다고 생각하면 됩니다. 그리고 실제로 그렇게 나열되어있는지 체크하고 싶다면 아래와 같이 코드를 구성해서 실행해보면 됩니다.
인텔 계열의 CPU에서는 아래와 같이 출력됩니다.
4. 바이트 정렬에서 주의할 점
CPU의 종류와 상관없이 운영체제 또는 운영환경에서 바이트 정렬을 지정하는 경우도 있습니다. 예를 들어 JAVA와 같은 프로그래밍 언어를 사용하여 프로그램을 개발하면 Java VM(Virtual Machine)에서 프로그램이 실행되는데 이 운영환경은 CPU와 상관없이 기본적으로 '빅 엔디언'을 사용합니다. 따라서 JAVA로 작성된 프로그램과 통신을 해야 한다면 데이터가 '빅 엔디언' 방식이라는 것을 고려하고 프로그램을 해야 합니다.
우리가 많이 사용하는 안드로이드 환경은 기본적으로 JAVA를 사용해서 프로그램을 많이 합니다. 그래서 안드로이드가 탑재된 하드웨어를 RISC 계열이라고 착각하는 사람들이 많은데 우리가 사용하는 안드로이드 시스템의 CPU는 대부분 CISC 계열입니다. 따라서 안드로이드 프로그램을 할 때 C 언어로 코드를 작성하면 '리틀 엔디언'이 적용되고 JAVA로 프로그램을 하면 '빅 엔디언'이 적용되기 때문에 주의해야 합니다.