스마트폰앱
- 전화 다이얼러
- 모바일 VOIP
- 안드로이드 프로그램
- 아이폰 앱 프로그램
- 네트워크 프로그램
- JAVA 자바
- UI DESIGN
- android JNI
- http post get
- 휴대폰 해외로밍


 친추
친추 카톡
카톡
라인상담
라인으로 공유
페북공유
◎위챗 : speedseoul

memcpy(memmory copy)와 memmove(memory move) 두 함수는 모두 특정 메모리를 다른 메모리로 복사할때 사용될 수 있다. 비주얼 스튜디오에서 이 두개의 함수의 차이는 사실상 큰 의미를 지니지는 않는다. 이 두함수의 사용법과 미묘한 차이점에 대해서 알아보고자 한다.
1. memcpy & memmove
- memcpy와 memmove 는 특정메 메모리 주소에서 원하는 크기만큼을 다른 곳으로 복사시켜준다. 함수의 생김새를 먼저 살펴보자. 헤더파일은 지난 포스팅에서 말한 것처럼 memory.h 또는 string.h 에 포함되어 있다.
함수 원형 | void* memcpy ( void* dest, void* src, size_t size ); |
src1 | 복사되는 메모리의 첫번째 주소 |
src2 | 복사할 메모리의 첫번째 주소 |
size | 복사할 크기 (바이트 단위임에 유의하자) |
반환값(return) | 성공시 dest, 실패시 NULL |
함수 원형 | void* memmove ( void* dest, void* src, size_t size ); |
src1 | 복사되는 메모리의 첫번째 주소 |
src2 | 복사할 메모리의 첫번째 주소 |
size | 복사할 크기 (바이트 단위임에 유의하자) |
반환값(return) | 성공시 dest, 실패시 NULL |
- move는 말그대로 이동한다는 의미이고, copy는 복사된다는 의미이지만, 실질적으로 결과는 복사되는것과 같기에 그냥 복사라고 표현했다. 위의 함수 2개를 살펴보면 어떤가? 생김새도 똑같고 매개변수도 동일하다. 다른건 이름뿐이다.이 두함수의 차이점에 대해서는 잠시 후에 알아보고 우선 두 함수의 사용방법부터 살펴보자.
char Love[10]= "ILoveYou";
char Hate[10]="IHateMe"; // (이러지말고 자신을 사랑합시다. -_-)
- 위와 같이 2개의 문자열이 있다. Hate 배열에서 Hate 문자열을 Love배열의 Love 자리에 복사시켜보겠다. 결론적으로는 Love 배열이 IHateYou와 같이 되기를 원한다.
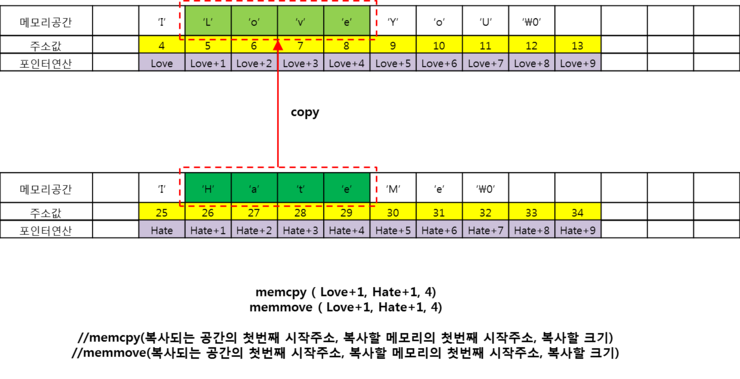
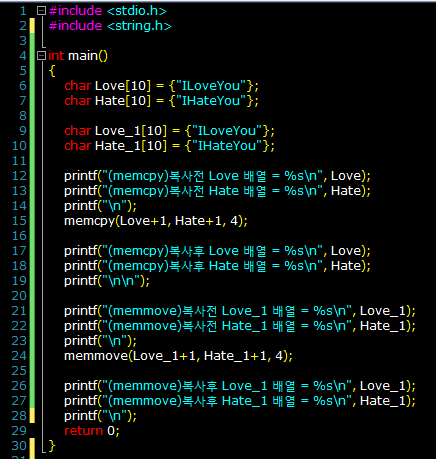
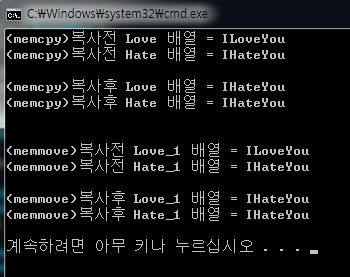
- 코드와 결과를 잘 보면 두가지 함수 모두 동일한 동작을 하여 잘 copy가 되고 있음을 알 수 있다. move라는 이름과 달리 원본도 잘 유지되고 있음에 유의하자. 원하는 구간을 원하는 사이즈만큼 복사할 수 있다는 장점이 있다. memcpy나 memmove는보통 특정 배열을 다른 배열로 복사시키고 싶을때 자주 사용한다. 1차원 배열을 예로 들어서 간단히 살펴보자면,
int a[10]= { 1,2,3,4,5,6,7,8,9,10 } ;
int b[10];
- 위와 같은 상황에서 a의 내용을 b에 복사하려면 어떻게 해야할까? 지금까지의 방법은 a배열의 각각의 원소를 b배열에 정확하에 대입을 해주면 된다. 즉
for(i = 0; i < 10; i++)
b[i]= a[i];
- 위와 같은 방법 말고 memcpy나 memove를 이용하면 반복문을 이용하지 않고
memcpy(b, a, 10 * sizeof(int));
- 와 같이 작성하면 된다. 이 한줄과 두줄차이인데 별 차이 없는거 아니냐고 하면 큰 할말은 없다. 다만 반복문이 많이 들어가 있어서 거추장스럽고 가독성이 떨어진다는 단점을 어느정도 커버해줄 수 있다. 또한 우리눈에는 안보이지만, 직접 배열의 원소를 일일히 복사하는 것보다 수행 속도 또한 빠르다. 그리고 2차원 3차원 배열이 된다면 이역시나 귀찮으며 지저분한 코드가 되는걸 한방에 방지할 수 있다. 그런걸 떠나서... 저렇게 단순하게 복사하는 것보다야..memcpy를 쓰면 뭔가 그럴싸해보이지 않는가? (-0-)
2. memcpy와 memmove의 차이
- 비주얼 스튜디어에서 결과적으로만 놓고보면 1번에서 우리가 봤던 것처럼 두 함수의 기능적인 차이는 없다. 그렇다면 대체 차이는 무엇이며 왜 두개의 함수가 존재하는가? (기능이 같다면 1개만 있어도 되겠지요.). 이 두함수의 차이점은 두가지 정도록 생각해볼수 있다.
A. memcpy는 메모리의 내용을 직접 copy하고, memmove는 copy할 메모리의 내용을 임시공간에 저장한 후 copy 한다. 결론인즉 memcpy의 속도가 더 빠르다는 것을 의미하며 반대로 보면 memmove가 더 안전하게 동작하는 것을 의미한다. 여기서 말하는 안전의 의미는 아래의 B항목에서 다시 생각해본다. 그러나 이 두함수는 처음에는 큰차이가 있었으나 지금은 그 차이가 좁혀져서 결국 가볍고 빠르지만 안전하지 못했던 memcpy는 어느정도 무겁던 memmove를 따라가고 있는 모습이다. 속도보다는 안전함이 우선되어야 함을 뒤늦게 인정한것일까?
B. memory를 copy할때 memcpy의 경우 자기 자신의 내용을 copy하여 자기 자신에게 덮어쓸때, 인접한 메모리에 의해 겹침 현상(overlap)이 일어난다. 이 문제는 메모리의 copy가 한칸한칸씩 반복해서 일어난다는 것을 의미하며 그림으로 보면 아래와 같다.
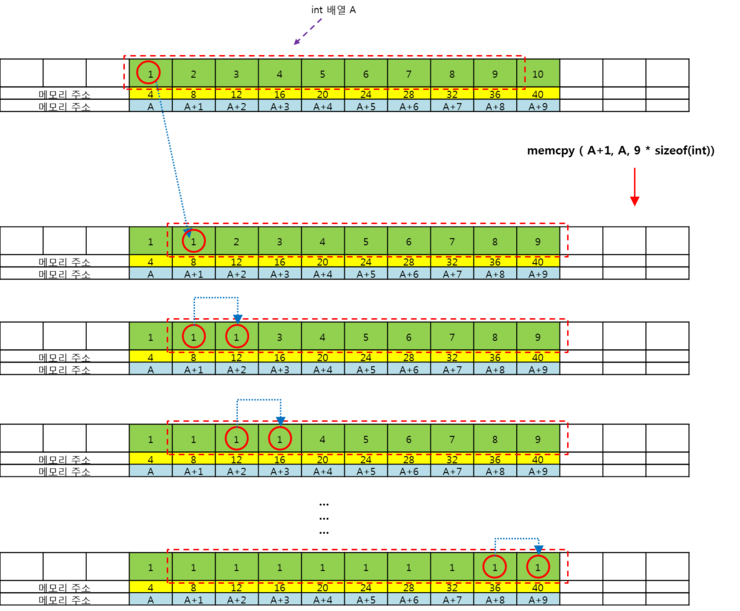
- 그림은 memcpy의 동작을 단계적으로 나타낸것이다. 위의 발깐색 점선 네모의 내용을 자기 자신의 A+1 즉 두번째 칸부터 복사해서 넣고자 하였다. 즉 처음부터 9개를 원래 있던 A의 두번째공간부터 복사를 하고자 한 것이다. 상식적인 생각으로 결과는 1,1,2,3,4,5,6,7,8,9 가 되길 원했다. 그러나 결과는 처참하게도 1,1,1,1,1,1,1,1,1,1이 나온다. memcpy는 위 그림과 같이 단계적으로 바로바로 복사를 해 나가기 때문에 한개를 복사하고 나면 다음 복사할 메모리가 이미 바뀌어 있는 것이다. 이것을 인접한 메모리 문제 또는 메모리의 복사시 오버랩핑이라고 말할 수 있겠다. 그리고 이러한 문제점을 안전하게 해결해주는 함수가 바로 memmove 인 것이다. memmove는 당연히 우리와 원하는 바와 같이 잘 복사가 된다. 임시공간에 복사할 내용을 저장해두고 거기에서 가져와서 복사를 하기에 원본을 건드리지 않는다고 볼 수 있다. 동작 모습은 아래와 같다. 한마디로 통째로 복사하는 것과 같은 효과를 볼 수 있다.
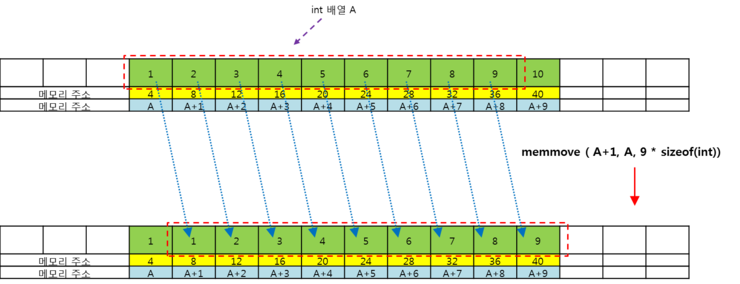
- 그러나 선술한 것처럼 현재의 VC에서 memcpy는 이러한 단점을 보완하여 memmove 와 같이 이제는 더이상 이런 오류는 발생하지 않는다. 하지만 C++빌더(볼랜드) 에서는 아직도 이런 오류가 발생하는 것으로 알고 있다. (혹시 바뀌었다면 지적해주세요.) 아마도 대부분의 이글을 읽는 초심자들은 VC를 사용할거라 생각한다. 이 경우에는 위와 같은 오버랩핑상의 오류는 걱정하지 않아도 된다. 실제 돌려보면 memcpy나 memmove는 모두 동일한 결과를 가져다 줄 것이다. 어떻게 보면 굳이 시사할 필요도 없다고 생각할지 모르겠으나, 오래전부터 이슈화된 문제이기에 한번 소개해보았다.
http://blog.naver.com/PostView.nhn?blogId=sharonichoya&logNo=220510332768&beginTime=0&jumpingVid=&from=section&redirect=Log&widgetTypeCall=true